Nos données Facebook : nouvelle aubaine électorale?

Depuis quelques années, les réseaux sociaux occupent une place prépondérante dans la société actuelle, en même temps qu’ils modifient drastiquement nos pratiques relationnelles, communicationnelles ainsi que l’accès à l’information. Facebook, avec plus de deux milliards d’utilisateurs, n’a pourtant plus la cote qui le caractérisait. En plus d’être boycottée par la jeune génération qui s’avère être plus séduite par Snapchat et Instagram (Utz, 2015 : 141), la plateforme souffre plus que jamais d’un manque de confiance de la part de ses fidèles. En cause, l’éclatement de plusieurs scandales relatifs à la divulgation des données de millions de profils Facebook à des sociétés privées et notamment Cambridge Analytica, pointée du doigt pour son implication durant la campagne électorale américaine de 2016, ce qui a déjà valu à Mark Zuckerberg plusieurs auditions devant le Congrès américain (Ward, 2018 : 133).
En exploitant les données et métadonnées de millions d’usagers américains, la firme britannique Cambridge Analytica a pu dégager des profils comportementaux, idéologiques et ainsi personnaliser l’information pour les électeurs (Ibid.). Au terme de cette vaste opération, c’est le candidat républicain que le peuple a plébiscité, le 8 novembre 2016. Bien que l’impact de cette stratégie électorale soit difficilement quantifiable, nous pouvons dès lors poser les interrogations suivantes : quels enjeux stratégiques peuvent résider derrière l’utilisation de traces numériques spécifiques, et quels sont les potentiels acteurs qui ont rendu possible ce ciblage électoral ?
Dans l’optique plus large d’observer les changements paradigmatiques et considérations épistémologiques liées à l’information et aux pratiques, notamment en raison de la traçabilité généralisée et de l’appropriation des traces par quelques puissances (Merzeau, 2013 : 119-121 ; Beaude, 2015 : 140), nous prendrons connaissance des modalités d’existence et de circulation des traces. Nous réfléchirons ensuite à la manière dont cette masse de données individuelles réinvestit les artefacts sociaux et afin d’illustrer ces bouleversements, nous nous attarderons sur le cas Facebook-Cambridge Analytica. Ainsi, nous tenterons de cerner les intérêts qui sous-tendent la relation entre l’un des géants du net et la société privée.

Zuckerberg devant le Congrès américain, avril 2018. Source : New York Times
I. Laisser « nos » traces?
Modalités d’existence et de circulation des traces
Nos multiples activités en ligne, bien qu’elles paraissent dématérialisées, laissent des traces immuables. Même chez l’usager le moins productif qui adopte un rôle de spectateur sur le web, le statut de passivité n’existe pas. Une couche documentaire peut être créée en fonction des journaux de connexion, données de localisation, du stockage des cookies, des transactions, clics, etc. Ces données qualitatives sont ainsi converties en données quantitatives et un traitement algorithmique économique et stratégique des bases d’intention permet de calculer une identité. Ces dernières ne peuvent être modifiées ; en effet, les traces se transforment en documents et demeurent dépendantes des géants du web, raison pour laquelle une trace n’est pas considérée comme personnelle mais comme une co-construction de l’environnement par les pratiques (Merzeau, 2013 : 122-123 ; Boullier, 2015 : 6).
« On ne fabrique pas une trace, on la laisse sans intention » (Merzeau, 2013 : 123)
A l’instar de Facebook, les conditions générales des différentes plateformes sont non négociables : une trace produite ne peut être modifiée à la source et est de ce fait déposée sans intention puisqu’elle est médiée par un groupe. Et depuis l’avènement des réseaux sociaux, les données collectées sur les individus et leurs relations se multiplient de manière exponentielle – Big Data, est désormais dans l’inconscient collectif (Merzeau, 2013 : 119-127 ; Boullier, 2015 : 18).
Ère du Big Data
Lorsque l’on évoque le terme Big Data, il est question de « massive amounts of electronic data that are indexable and searchable by means of computational systems, stored on servers and analysed by algorithms» (Isaak, 2018 : 56). En raison de la détention de ces données par des compagnies telles que Google, Twitter et Facebook, ce stockage massif constitue actuellement un débat autour de l’impact sociétal que la collecte et l’utilisation de données génère, ainsi que le risque qu’il représente pour la vie privée des citoyens, en raison entre autres de la capacité de surveillance sans précédent à laquelle il est associé (Ibid. ; Gonzalez, 2017 : 9 ; Beaude, 2015).
« After Eisenhower, you couldn’t win an election without radio. After JFK, you couldn’t win an election without television. After Obama, you couldn’t win an election without social networking. I predict that in 2012, you won’t be able to win an election without big data. » Alistair Croll
Appropriation hypercentralisée
Ces dernières années, l’activité d’achat et de vente de données d’utilisateurs par les puissances du net s’est élevée au rang d’industrie – à des finalités stratégiques variées, et ce par une quantité moindre d’acteurs (Gonzalez, 2017 : 9 ; Beaude, 2015 : 140). Les computer sciences, à l’instar du marketing, génèrent leurs propres outils de suivi de la vie sociale. La puissance de calcul et la traçabilité inédite du Big Data se passent ainsi des interprétations des sciences humaines et sociales, (Boullier, 2015 : 5). Même s’il y a une distinction à faire entre data et knowledge (Barnes, 2013 : 299), les pratiques se retrouvent désormais au centre d’une hypertraçabilité, dont les acteurs majeurs du web ont un accès quasi-exclusif, ce qui permet la remédiation des traces de relations sociales (Beaude, 2018 : 9).
Dépendantes des dispositifs des collecte, ces traces bouleversent les modes de production de connaissances. On assiste à une appropriation de traces massive dans des environnements spécifiques, et leur traitement demeure opaque – ce qui accentue l’asymétrie entre les puissantes firmes détentrices de nos données personnelles et le non-contrôle que les individus ont vis-à-vis de leur empreinte numérique ; Google, Facebook, les opérateurs, etc. étant capables d’associer et de croiser les données et d’en produire une analyse pouvant reposer sur des motivations diverses (Boullier, 2015 : 7 ; Severo & Romele, 2017 : 16 ; Beaude, 2018. : 2-20). En l’occurrence, c’est sur l’une des stratégies électorales récemment employée que nous allons nous attarder pour essayer d’en cerner les enjeux.
II. Le cas Cambridge Analytica
Etat des lieux de la firme
La firme britannique Cambridge Analytica, dont l’intention ouvertement explicite était de « vendre aux gouvernements et organisations privées des produits analytiques et persuasifs susceptibles d’entraîner des changements comportementaux chez des audiences ciblées », provoque de nombreux échos aujourd’hui, deux ans après sa fermeture en 2017 (Ward, 2018 : 138 ; Cadwalladr, 2017 ; Cadwalladr & Graham-Harrison, 2018). Auparavant nommée SCL Group, la compagnie a œuvré notamment en faveur du Brexit, d’élections en Afghanistan, au Pakistan en plus de la campagne de Donald J. Trump. C’est en 2014 que l’entreprise a pris un tournant différent (Persily, 2017 : 65 ; Cadwalldr, 2017 ; Common, 2018 : 1).
« Putting the right message in front of the right person at the right moment is more important than ever » Cambridge Analytica
L’un des atouts de la société est l’utilisation d’un « mind-reading software », conçu par deux psychologues de Cambridge University’s Psychometric Centre qui avaient pour ambition d’étudier la personnalité des individus en quantifiant 5 traits de personnalité (Openness, Conscientiousness, Extroversion, Agreeableness, Neuroticism), grâce par exemple aux likes de Facebook (Cadwalladr & Graham-Harrison, 2018 ; Gonzalez, 2017 : 9-10 ; Ward, 2018 : 133).
Aux mains de Cambridge Analytica, cet outil allié à d’autres technologies a permis de constituer des profils de 5000 data points. En plus des données socio-démographiques standards, ont pu être recensées des informations relatives à l’orientation sexuelle, au point de vue politique et religieux, à l’usage de substances addictives, etc., la finalité étant d’élaborer des publicités ciblées ou du moins des contenus spécifiquement individualisés (Berendt & Dettmar, 2018 : 55-56 ; Forest, 2018 : 47 ; Ward, 2018 : 133 ; Cadwalladr, 2017).
Utilisation du microtargeting
Lors de la campagne électorale de Trump, ce sont plus de 220 millions de profils qui ont pu être traduits en contenus à destinataires ciblés. En fonction de l’analyse algorithmique de la personnalité relative à l’empreinte numérique, Cambridge Analytica a été en mesure de faire du ciblage comportemental sans que la visée soit pour autant informative (Ward, 2018 : 133 ; Gonzalez, 2017 : 9-12).
Selon Kosinski, l’un des créateurs de l’outil psychométrique, « computers see us in a more robust way than we see ourselves » – 150 likes Facebook d’un individu suffiraient d’après lui pour que le modèle algorithmique prédise plus justement le comportement que son conjoint. Christopher Wylie, ancien collaborateur de Cambridge Analytica qui est à l’origine de la médiatisation de l’affaire en lançant l’alerte début 2018, caractérise les likes Facebook comme weapons, susceptibles de créer des contenus de persuasion une fois traités par les modèles (Cadwalldar, 2017).

Christopher Wylie s’exprime au Parlement britannique en mars 2018. Source : c-span
Parti pris de Facebook
L’affirmation de l’entreprise de Zuckerberg est tranchée : le réseau n’essayerait jamais de contrôler des élections (Forest, 2017 : 42). L’assignation à la transparence est incarnée par l’entreprise mais les traces que nous laissons ne bénéficient d’aucune individualisation contextuelle et l’accès à ces données demeure restreint (Beaude, 2015 : 128). Sachant qu’en 2012 déjà, plus de 845 millions d’utilisateurs étaient actifs mensuellement, que près de 3 milliards de likes et commentaires étaient générés quotidiennement et que 100 milliards d’amitiés avaient été créées, il est convenable d’imaginer que la masse de données est conséquente (Forest, 2017 : 39).
Alors que Cambridge Analytica a commencé à traiter des millions d’informations dès 2014, Facebook a omis au même titre que Cambridge Analytica le lien qui existait entre les deux entreprises. D’un côté, le géant bleu affirmait mettre la privacy sur un piédestal et de l’autre, l’organisation britannique admettait exploiter des données personnelles issues du web, mais niait l’utilisation des données Facebook (Cadwalladr, 2018).
En 2016, les recettes publicitaires sont passées de 3,1 milliards en 2011 à plus de 25 milliards, avec l’essor de la publicité personnalisée, et il semble intéressant de pointer le fait que le taux de pénétration sur internet des américains est bien plus élevé que la moyenne globale, 88% contre 50%. La plateforme Facebook ne fait pas exception, puisqu’en comparaison à la moyenne internationale qui est de 55%, plus de 70% des américains qui possèdent un compte l’utilisent de manière quotidienne (Cadwalladr, 2018 ; Downes, 2018 : 11).
Mars 2018, Zuckerberg s’exprime suite à la divulgation de documents qui explicitaient le lien entre Cambrige Analytica et le géant bleu.
Source : Facebook
Après l’alerte lancée par Christopher Wylie, préoccupé par le potentiel impact de son activité au sein de Cambridge Analytica face à l’utilisation des données, le géant américain a admis « qu’il fallait agir pour apaiser les inquiétudes qui sous-entendaient qu’il avait été responsable de désinformation pendant la campagne » (Forest, 2017 : 39). En avril 2018, l’ampleur de l’affaire a amené Zuckerberg devant le Sénat américain, où il a affirmé avoir commis une « erreur » et se disait prêt à coopérer avec le Sénat pour réguler l’industrie des médias sociaux, avançant toujours le dessein premier du réseau : la connexion sociale et le partage de contenus. Aujourd’hui, la tendance est à la méfiance : en effet, de nombreux mouvements comme deletefacebook prônent la suppression des comptes, parallèlement à la tournée en dérision du CEO de Facebook sur les réseaux sociaux (Lapaire 2018 : 100-103).
Les investisseurs discrets de Cambridge Analytica
Le nom de Steve Bannon peut sembler familier pour les intéressés de politique américaine – en plus d’avoir été conseillé à la Maison Blanche, il était à la tête de la campagne électorale de Trump, et a notamment agi en tant que CEO au sein de Breitbart News, un média politique américain conservateur, intimement lié au Media Research Center, une organisation libérale qui a pour dessein de surveiller les médias du pays (Bennett & Livingston, 2018 : 126 ; Codwalladr, 2017).

Steve Bannon, figure politique américaine et investisseur de Cambridge Analytica
Photo : Tony Gentile/Reuters
C’est en 2014 que Steve Bannon investit pour le lancement de Cambridge Analytica, aux côtés d’un fantôme de la scène médiatique internationale, qui côtoie pourtant les élites politiques et s’avère être la pierre angulaire de l’affaire : Robert Mercer (Muhammad, 2017 : 4 ; Albright, 2016 : 4 ; Cadwalladr & Graham-Harrison, 2018).

Robert Mercer, CEO de Rennaissance Technologies, investisseur de Cambridge Analytica
Photo : BJ Nemeth
Source : cnbc
Génie de l’informatique, pionner du trading algorithmique et de l’intelligence artificielle, il a d’abord exercé chez IBM (Albright, 2016 : 4 ; Muhammad, 2017 : 3 ; Cadwalladr, 2018). C’est en acquérant un haut grade chez Renaissance Technologies, une entreprise utilisant des algorithmes pour modéliser les marchés financiers, qu’il s’est constitué une fortune qui lui a permis par la suite d’investir des fonds considérables bien avant Cambridge Analytica ; il est en effet l’un des donateurs majeurs de Breitbart News, et finance The Heartland Institute, une organisation réputée pour défendre des thèses climatosceptiques, en plus de divers soutiens aux candidatures républicaines et notamment celle de Donald Trump, pour laquelle près de 15 millions de dollars ont été investis (Forest, 2017 : 45 ; Cadwalladr, 2017).
Donations by the Mercer Family Foundation 2008-2016
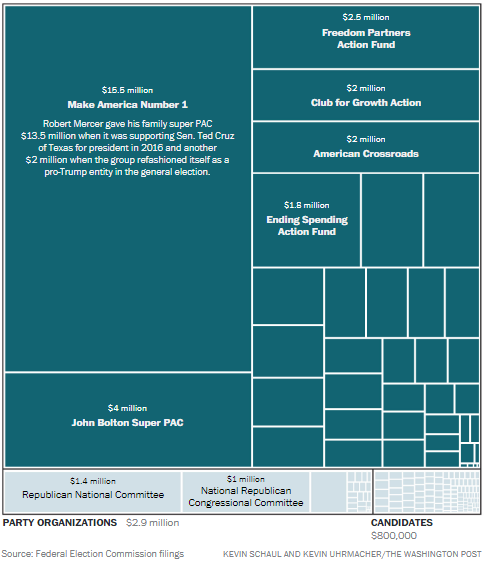
Source : The Washington Post
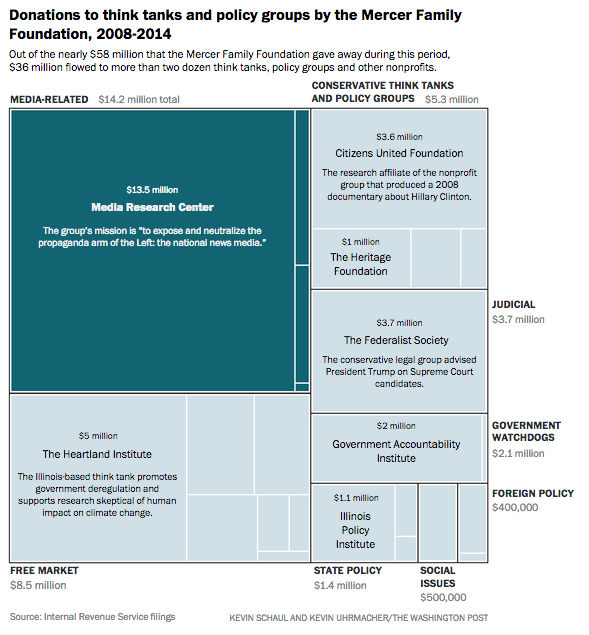
Source : The Washington Post
Les enjeux stratégiques semblent être au service d’idéologies et d’intérêts personnels, et cette méthode observée soulève des interrogations quant au poids des décisions d’une poignée de personnes à une si grande échelle. Avant d’essayer de mesurer l’impact et la crédibilité de la démarche ainsi que les questionnements qu’elle soulève, nous allons énumérer divers points qui caractérisent les nouvelles formes d’action relatives aux données sociales et les bases sur lesquelles elles reposent.
III. Bouleversements paradigmatiques
Accès à l’information
Ces dernières années, l’accès à l’information ainsi que les mediums utilisés ont drastiquement évolué, ce qui remet en cause non seulement la manière dont les données sont récoltées, mais également l’usage qui en est fait (Beaude, 2015 : 133). Auparavant, les recensements socio-démographiques formatés par des administrations publiques pour des Etats constituaient la base des données sur le monde social et nous assistons actuellement à un tournant paradigmatique de la raison de l’information et les data sont élevées au rang de types de connaissances. Elles peuvent désormais être synonymes de pouvoir – les traces étant utilisées pour créer des profils comportementaux individuels en croisant les données, pour un monitoring de l’information à un coût moindre (Boullier, 2013 : 13 ; Diallo, 2011 ; Ward, 2018 : 127 ; Downes, 2018 : 11 ; Berendt & Dettmar, 2018 : 56).
Le monde numérique semble octroyer une place de plus en plus faible aux sciences humaines et sociales ; en fonction des traces récoltées, il est désormais possible de modeler une information personnalisée, plaçant l’individu dans un monde de plus en plus propre. L’information livrée à l’individu suit désormais des concepts de réactivité et non plus de réflexivité comme auparavant, lorsque la communication de masse était la norme (Cadwalladr, 2017 ; Merzeau, 2013 : 130 ; Boullier, 2013 : 5).
En effet, les computational sciences visent un principe d’efficience, basé sur la prédiction – des problématiques sociales sont importées dans les mathématiques, la physique et l’informatique (Beaude, 2018 : 16) – et c’est précisément cette épistémologie actuelle qui est centrale, en contraste avec la notion de compréhension des phénomènes sociaux par la réflexivité, qui « autorise la pensée de la relation elle-même » (Ibid : 27-28). Ce n’est plus l’interprétation qui est au cœur mais bien l’efficience, qui s’appuie sur la prédiction et non sur la compréhension (Ibid, 2018 : 3).
Visibilité
« We live in a new world, we do things differently. This is an Apple and Google world that reaches if not the sky, then at least to the cloud »
(Barnes, 2013 : 298 )
En raison de cette méthode récente de récolte de données, Facebook ainsi que d’autres entreprises multinationales engendrent un impact considérable sur nos relations sociales. Internet, de par sa capacité à réduire les distances, réagence notre environnement et particulièrement le rapport que nous avons à l’espace. Cet espace se profile en tant que vecteur de transformation médié par des moyens de transmission conséquents. Ces représentations « renouvellent les conditions de visibilité » et posent désormais des questions d’accessibilité de données, ainsi que des problématiques de vie privée (Beaude, 2015 : 133-144 ; Beaude, 2018 : 6).
Produites essentiellement par la remédiation numérique des pratiques, les puissances du web ont donc désormais un pouvoir sans précédent sur les données – la visibilité des médiations sociales numériques est partagée par un nombre d’acteurs restreint, et c’est cette hypercentralité des médiations qui est au centre du bouleversement des pratiques. Les conditions générales, l’architecture ainsi que le code sont gérés dans une opacité contrôlée (Beaude, 2013 : 134 ; Beaude, 2015 : 149). Les mêmes plateformes produisent, calculent et publient les traces (Boullier, 2013 : 13).
IV. Questionnements soulevés
Mesure de l’impact
Les différentes plateformes telles que Wikipédia, Google, Amazon, en plus du cas Facebook démontrent jour après jour à quel point les pratiques sont en recomposition, et cela à un rythme soutenu (Beaude, 2018 : 4). Le cas de Cambridge Analytica a la particularité de mettre en lumière la manière dont les nouvelles technologies peuvent élaborer des contrôles de gestion (Gonzalez, 2017 : 12). Mais l’impact réel de la stratégie électorale de Trump dans le cadre de cette reconfiguration de pratiques est difficilement délimitable et quantifiable (Ward, 2018 : 138).
If the method was, indeed, used, it is furthermore unknown to what degree it was effective in influencing the voting behavior of the electorate. (Ward, 2018 : 138)
En effet, malgré les sommes investies et la volonté de Cambridge Analytica de proposer des contenus spécifiques aux électeurs indécis afin de les persuader de glisser un bulletin républicain dans l’urne, de nombreux autres éléments ne peuvent être négligés. Avant de faire son apparition sur la scène politique, le showman Trump s’est installé durant 14 saisons dans le salon des américains au cœur de la série The Apprentice, en plus de maintenir l’attention en agissant abondamment sur les réseaux sociaux et particulièrement Twitter, à côté des rencontres et meetings formels de campagne électorale, etc. (Gonzalez, 2017 : 11 ; Bennet & Livingston, 2018 : 130).
Perception de la crédibilité
Peut être remis en question évidemment le parti pris des analyses algorithmiques partant du principe que bigger is better, qui suivent l’idée selon laquelle une quantité démesurée de data points permettrait d’avoir accès aux tréfonds véritables d’un individu (Gonzalez, 2017 : 10). Un des risques peut être la réduction de l’individu voire du monde à ses traces (Severo & Romele, 2017 : 9).
En plus de cela, en implémentant des biais cognitifs, des préconceptions avant de livrer une information ou en limitant son accès, il n’y a pas de garantie d’information factuelle permettant à l’électeur de construire un raisonnement rationnel (Ward, 2018 : 137) – sachant que les contenus à visée persuasive reposent régulièrement sur des implications émotionnelles, lesquelles sont susceptibles d’amplifier leur diffusion et accroître leur chance de devenir des contenus viraux. Ces contenus provoquent des asymétries au sein de la population qui bénéficie d’informations divergentes, rendant les individus inégaux face notamment à certaines représentations qui leur sont soumises. (Isaak, 2018 : 57 ; Berendt & Dettmar, 2018 : 56 ; Downes, 2018 : 11-14 ; Brady & al. 2016 : 7313-7314).
Conclusion
De nouvelles sources d’information mettent en évidence le pouvoir des plateformes dans le bousculement de l’ordre démocratique, et ce possiblement à travers du profilage psychologique qui peut conduire à des formes de persuasion (Benett & Livingston, 2018 : 122 ; Berendt & Dettmar, 2018 : 56).
Après avoir observé la dépendance des traces vis-à-vis des lieux dans lesquels elles se constituent, le cas Cambridge Analytica et Facebook a pu illustrer la manière dont des puissances bénéficient d’une forte capacité de réappropriation et d’action sur les données numériques (Merzeau, 2013 : 125). L’émergence de ces pratiques restructurées pose des questions relatives à l’impact sociétal des enjeux stratégiques résidant dans l’utilisation faite de nos données.
Alors que la participation ainsi que l’accès aux archives a toujours été considéré comme une marque de la démocratie, nous assistons aujourd’hui à une capitalisation de la connaissance où l’opacité est de mise (Beaude, 2015 : 149-150). Les traces vivent une existence autonome et ne constituent pas la propriété de l’individu, ce qui le prive de l’« organisation du mémorable » en plus de fermer la porte à la dimension sociale de l’amnésie (Merzeau, 2013 : 127-128).
Les données actuelles représentent une masse incommensurable (Merzeau, 2013 : 127), et pourtant leur quantité n’apporte pas d’élément éclairant quant à leur qualité (Beaude, 2018 : 30). En imaginant une data shadow qui représenterait notre double numérique dont on pourrait cerner la silhouette (Howard, 2003 : 238), n’oublions pas que le travail de mise en scène n’est pas négligeable sur internet ; à l’ère pendant laquelle de nombreux phénomènes sociaux sont réduits à des formules statistiques, il semble pertinent de garder en mémoire que « les coulisses peuvent constituer l’essentiel de pratiques invisibles » (Goffman, 1973) (Beaude, 2015 : 148-151).
Références bibliographiques
Albright, J. (2016). How Trump’s campaign used the new data-industrial complex to win the election. USApp–American Politics and Policy Blog.
Barnes, T. J. (2013). Big data, little history. Dialogues in Human Geography, 3(3), 297-302.
Beaude, B. (2015). Les virtualités de la synchorisation (No. EPFL-ARTICLE-207923, pp. 123-143).
Boris Beaude, 2018, « (re)Médiations numériques et perturbations des sciences sociales contemporaines», in Sociologie et sociétés (à paraître).
Beaude, B. (2015). Spatialités algorithmiques. Traces numériques et territoires, 135-162.
Bennett, W. L., & Livingston, S. (2018). The disinformation order: Disruptive communication and the decline of democratic institutions. European Journal of Communication, 33(2), 122-139.
Berendt, B., & Dettmar, G. (2017). IF YOU’RE NOT PAYING FOR IT YOU ARE THE PRODUCT: A LESSON SERIES ON DATA, PROFILES, AND DEMOCRACY. In Paderborn Symposium on Data Science Education at School Level 2017: The Collected Extended Abstracts (p. 55)
Boullier, D. (2015). Les sciences sociales face aux traces du big data. Revue française de science politique, 65(5), 805-828.
Brady, W. J., Wills, J. A., Jost, J. T., Tucker, J. A., & Van Bavel, J. J. (2017). Emotion shapes the diffusion of moralized content in social networks. Proceedings of the National Academy of Sciences, 114(28), 7313-7318.
Cadwalladr, C., & Graham-Harrison, E. (2018). The Cambridge Analytica Files. I made Steve Bannon’s psyhological warfare tool’: meet the data war whistleblower.
Cadwalladr, C. (2017). Robert Mercer: the big data billionaire waging war on mainstream media. The Guardian, 26, 2017.
Common, M. F. (2018). Facebook and Cambridge Analytica: let this be the high-water mark for impunity. LSE Business Review.
Downes, C. (2018). Strategic Blind–Spots on Cyber Threats, Vectors and Campaigns. The Cyber Defense Review, 3(1), 79-104.
Forest, S. C. (2017). The Race to Control the Voter: Big Data and the Transformation of the Election
Gonzalez, R. J. (2017). Hacking the citizenry?: Personality profiling,‘big data’and the election of Donald Trump. Anthropology Today, 33(3), 9-12.
Howard, P. N. (2003). Digitizing the social contract: Producing American political culture in the age of new media. The Communication Review, 6(3), 213-245.
Isaak, J., & Hanna, M. J. (2018). User Data Privacy: Facebook, Cambridge Analytica, and Privacy Protection. Computer, 51(8), 56-59.
Kennedy, H. (2018). How people feel about what companies do with their data is just as important as what they know about it. Impact of Social Sciences Blog.
Lapaire, J. R. (2018). Why content matters. Zuckerberg, Vox Media and the Cambridge Analytica data leak. ANTARES: Letras e Humanidades, 10(20), 88-110.
Merzeau, L. (2013). L’intelligence des traces. Intellectica-La revue de l’Association pour la Recherche sur les sciences de la Cognition (ARCo), 1(59), 115-135.
Muhammad, I. (2017). ROBERT MERCER.
Persily, N. (2017). The 2016 US Election: Can democracy survive the internet?. Journal of democracy, 28(2), 63-76.
Severo, M., & Romele, A. (2017). Traces numériques et territoires. Presses des Mines via OpenEdition.
Utz, S., Muscanell, N., & Khalid, C. (2015). Snapchat elicits more jealousy than Facebook: A comparison of Snapchat and Facebook use. Cyberpsychology, Behavior, and Social Networking, 18(3), 141-146.
Ward, K. (2018). Social networks, the 2016 US presidential election, and Kantian ethics: applying the categorical imperative to Cambridge Analytica’s behavioral microtargeting. Journal of media ethics, 33(3), 133-148.

